
Архитектура системы FRANK
Архитектура системы FRANK
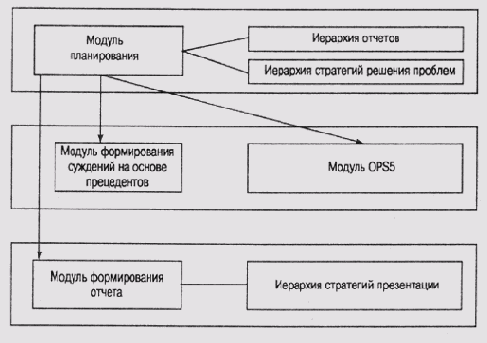
Поток управления в системе можно описать в терминах последовательности шагов обращения к источниками знаний, которые манипулируют данными на доске объявлений (см. об этом в главе 18). Вместо того чтобы по очереди описывать каждый источник знаний, мы представим основные этапы обработки, в результате которых формируется и выполняется план построения отчета. Исходные данные имеют формат перечня тем (например, нужно ли, чтобы определенная медицинская процедура была подтверждена случаями из практики), а выход системы — это отчет, в котором темы изложены в соответствии с заявленными предпочтениями.
- Начальный источник знаний формирует скелет отчета, в котором зарезервированы разделы для определенных фрагментов информации.
- Затем формируются стратегии для отдельных разделов, для чего привлекаются другие источники знаний. Стратегии извлекают планы разделов из библиотеки планов.
- Специальный источник знаний конкретизирует каждый план и выполняет его, активизируя соответствующую цель. После формирования цепочки "цель—подцель" удовлетворяются цели нижних уровней. Как правило, такие подцели заполняют слоты шаблона отчета.
- Другие источники знаний проверяют совместимость разделов отчета. Если противоречия не обнаруживаются, выходной документ формируется в соответствии со стратегией презентации. В противном случае корректируется план.
Комбинируя тип отчета и стратегию, система строит определенный план, в котором, в частности, есть место и для информации о прецедентах, подходящих для текущего диагноза. Наиболее подходящий прецедент выбирается по совпадению большинства симптомов с анализируемым случаем, но возможны и другие стратегии.
Например, более аргументированная стратегия может потребовать, чтобы прецедент считался подходящим, если:
- он совпадает по большинству симптомов с текущим случаем; Ф имеет совпадающий диагноз;
- не содержит никаких свойств, подобных прецедентам, имеющим другой диагноз.
Формирование запросов к базе прецедентов выполняется под присмотром источника знаний, который играет роль механизма планирования задач. Такие запросы могут быть частичными, т.е. определенные атрибуты запроса заполняются значениями по умолчанию. Этот же модуль обеспечивает различные варианты поведения системы, если поиск не даст результата. В частности, могут быть изменены ограничения на значения параметров в запросе, после чего поиск возобновляется.
Система FRANK поддерживает две методологии формирования суждений на основе прецедентов:
- стиль поиска ближайшего соседа, как в системе CHEF;
- группирование прецедентов по степени "похожести" в соответствии с определенным набором факторов верхнего уровня, как в системе САТО.
Такая гибкость в выборе методологии позволяет уравновесить влияние целей высокого уровня и результатов низкого уровня.